Now that we’ve looked at what an algorithm is, we can go a bit deeper and take on one of the most common section of algorithms: Recursion
Recursive algorithms are actually quite easy to understand and we often use it intuitively in our daily life. Recursion only means, that a function calls itself. To illustrate things, we’ll be taking the calculation of the Fibbonaci numbers as an example. The following image shows the first few numbers and a mathematical definition:
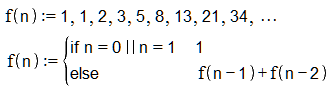
So as you see the function f has one initial values for n = 0 and n = 1. For every other n, we call the function f recursively.
Since we as programmers are not that interested in the mathematical terms, here goes a very easy and straight forward implementation:
unsigned int f(unsigned int n) {
if(n == 0 || n == 1)
return 1;
else
return f(n-1)+f(n-2);
}
As you see it nearly matches the mathematical definition after all. If we now were to test this function, we’d soon notice how long it takes to figure out for example n = 50. So how do we make it faster? To answer that question, we’ll first have to take a look at why the algorithm is so slow and for that we need to take a closer look at how applications work in general.
Every application gets a memory area with fixed size, aka as stack, on which it does all its local operations. For every recursion we’re making, all the currently active variables, states, etc. have to be saved onto the stack and only then the “content” for the new function will be loaded. Doing this a few thousand times will crush your performance and can essentially even lead to stack overflows, which means your application will crash.
One way to fix this, is to trade some memory for performance. The main problem of the recursive algorithm is, that it will calculate the same number over and over again. You’ll end up with a tree which is built with the same sub-trees all over again:
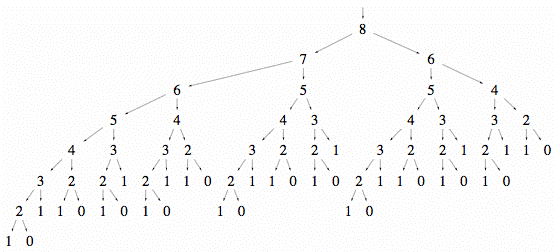
With the acquired knowledge we can turn the whole algorithm around and instead of starting at the top, we start at the bottom, save every result in between and then apply the formula for n+1. Now we can immediately look up what the result for any n-i is, we only had to calculate it once and we don’t need to recursively call the function.
#include <vector>
unsigned int f(unsigned int n) {
std::vector<unsigned int> mem(n+1, 0);
mem[0] = 1;
mem[1] = 1;
for(unsigned int i = 2; i < n+1; ++i)
mem[i] = mem[i-1] + mem[i-2];
return mem[n];
}
You can obviously also use an array if you’d like, but I prefer to use modern containers, which should also assert for out of bound mistakes. The pre-allocation of the vector will give us a bit a better performance due to the fact that, vector won’t have to resize itself while inserting new numbers, but in comparison to the recursive algorithm this won’t be noticeable anyways.
Although this might seem to have worked just for this specific case, the used principles can be applied to quite a few recursive algorithms and is called memoization (no it’s not memorization). Here are the steps again:
- Find the recursive formula.
- Implement a straight forward algorithm.
- Bottom-Up the algorithm and ‘memo(r)ize’ all the steps.
Keep in mind though, that this method is just one way to optimize algorithms and that it might work for other problems, but not be the best way to do it.
I hope my article wasn’t too unstructured and confusing, but gave you some insight or refreshment on that topic.
A complete example with benchmarking can be found on GitHub.